为何要用公司内部的框架, 直接跑服务不好么?
简单的部署运维 pm2 + (koa or express) + MongoDB
可能遇到的问题:
- 日志怎么管理?
- 有没有服务监控与告警?
- 怎么快速部署, 扩容?
- 运维管理还得用命令行?
- 负载均衡咋办?
结论: 尽可能接入公司现有的运维与技术框架, 减少开发成本与运维成本,提高系统的稳定性和安全性
tips: 虽然目前 pm2 等工具已经非常强大, 也提供现有的运维监控平台,但是由于服务运维是关键的路径,直接使用第三方还是需要详细研究, 目前还是使用自研的产品比较好
公司现有的管理运维平台
Node in tars – Node.js 大规模商用平台
TSW – 针对web前端开发同学的server端web开发解决方案 https://tswjs.org/
Node in tars :
- 无需进行任何代码层面的的变更
- 在线的进程管理系统与运维平台
- 实时的日志查询
- 系统用量与请求监控
- 快速部署工具
###SNG-TSW
- 开箱自带内部通用组件接口特性
- TSW 作者维护 tsw 包的版本, 机器负责人负责机器包更新
- 实时日志系统与服务端抓包
- 与包发布发布系统耦合
- 开源框架的兼容
- 路由,全局变量,常用 util
一个技术框架与运维体系的应有的功能与组成
- 进程管理
- 请求监控 与 用量监控
- 日志与监控告警平台
- debug 定位问题
- 接入公司内部标准组件
- 开发流程
- 部署流程
- 启动,停止,重启,热重启
- 扩容与迁移
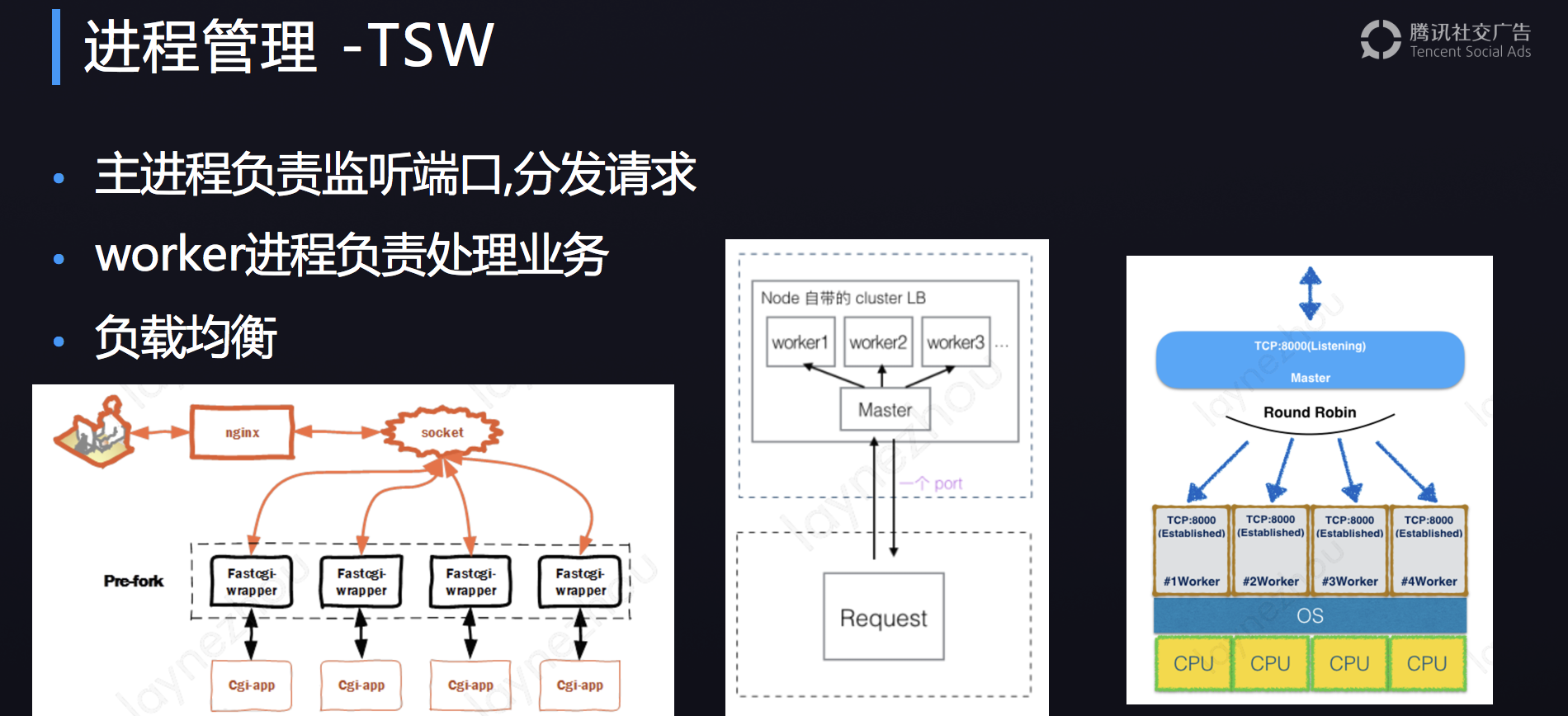
进程管理
TSW:
- 主进程负责监听端口,分发请求
- worker进程负责处理业务
- 负载均衡
Node in tars:
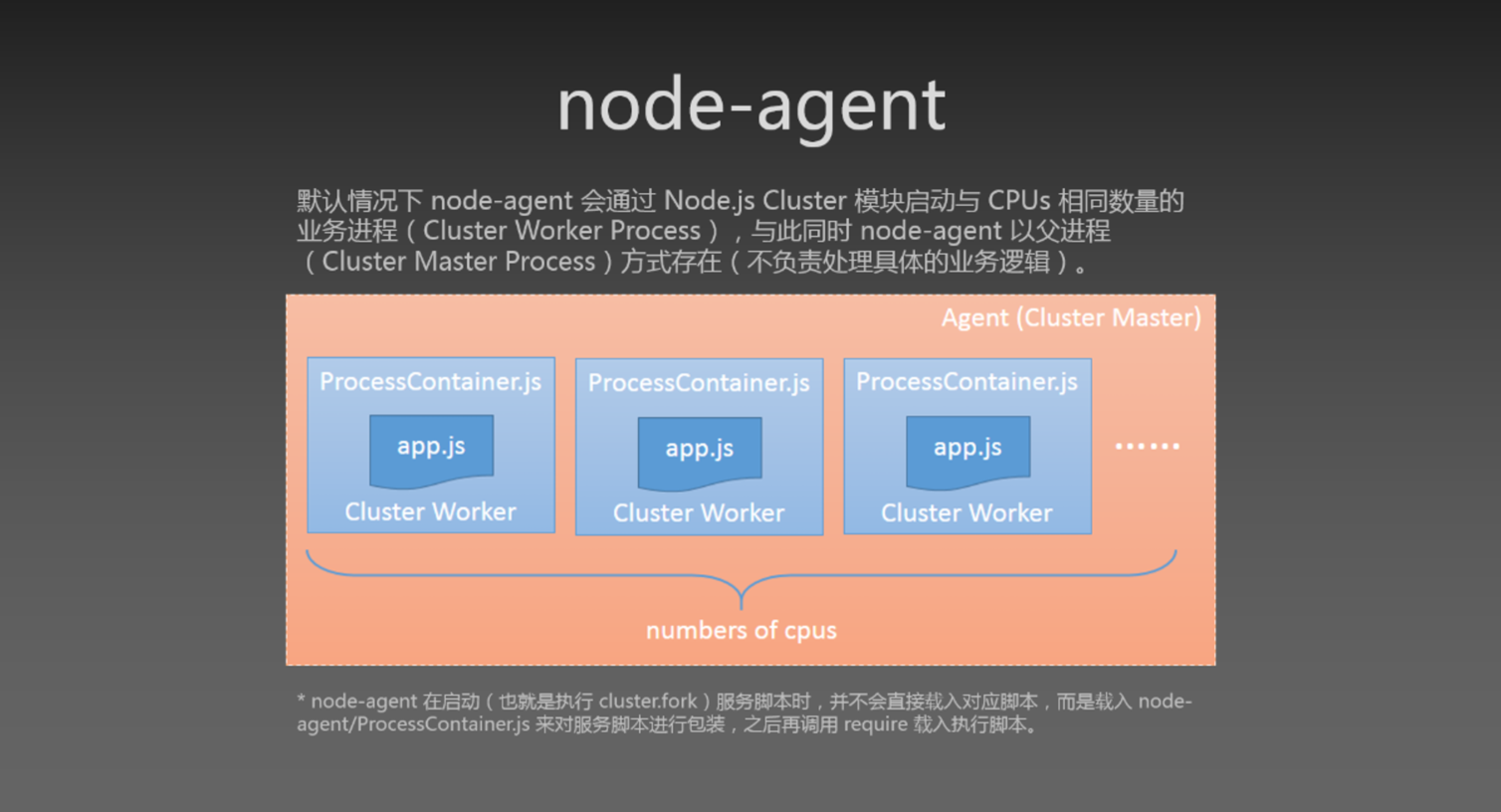
tips: 由主进程负责监听端口,接收新连接后再将连接循环分发给工作进程
有一种基于round-robin 算法的模型,master 进程创建socket, 绑定地址端口, 同时负责监听
当获取到新的连接之后(调用 accept 方法与客户端建立 tcp 连接), 再将这个连接分发到指定的 worker 进程, 这里如何分发到指定的 worker 进程是可控的, 这里使用了 round-robin 算法, 当然还有其他的算法也可以用于请求的分发.
请求监控用量监控
- tars:
- 系统集成自带的监控
- SET 内存、CPU用量数据,以及 eventloop 滞后数据
作者给出的定义: js主线程处理不过来了,计算方法为: setTimeout 2s,然后减去2s, 得到的非0值就是滞后时间
我的理解: EventLoop 滞后根据 js 的 event 事件模型中的概念来看的话: 可以作为一个指标来衡量 event 事件队列的长度, 比如
1 | function a(){ |
这里 alert(1), 会滞后 alert(2) 执行, 这个之间的时间差可以用来作为 eventloop 滞后数据指标
(这是我分析了event 事件的运行机制得出, 可能不一定准确, 有错误希望指出)
日志
TSW:
- 实时日志
- 历史日志
- 服务器本地日志
Node in tars:
- Console 重定向到特定的日志
- 管理端动态变更日志基本
- 实时日志查看客户端
监控告警平台
TSW:
- 邮件告警, 自主配置通知者(业务模块、请求头、错误堆栈等)
- 模调低于阈值98%告警(短信、内部IM信息通知)
tars:
- 系统/网络层监控(系统负载,磁盘,网络连通性)
- 应用层监控(ps,http,log,port)
- 业务层监控: pp监控(自定义多维度上报)
debug 定位问题
TSW:
- 服务端抓包 (毫秒级延时)
- log(14天)
- 服务器端日志
- 染色
tars
- 实时日志查看
- 管理平台更改日志输出级别
- 染色 平台
开发流程与部署流程
TSW:
- 推荐本地搭建 tsw 环境调试
- 需要应用接入 tsw(成本较低)
- 支持 文件 提单发布
- 包发布打包发布(推荐)
tars
- 无需配置环境, tars 只是一个运行容器, 本地开发调试
- nodetools 发布工具
- Svn, git 在线编译与发布
tips: 在 tars 中,正式部署分为:编译与发布两个环节。
编译环节中,先在平台上配置 SVN / GIT 并打 TAG 之后即可编译。
编译完成了之后即可选择不同的版本进行发布,一旦发布出现问题则可快速进行回滚操作。
启动,停止,重启,热重启
- 包发布包中设置重启脚本
- 安装或升级完成之后直接点击热重启或者重启
- tars也支持在管理页面重启应用等操作
- reload方案: 60秒刷新cache , 对性能损耗3%
扩容
- TSW: 包发布自动化一键安装(安装包,下发配置)
—————-分割线—————
一点小改变: 在docker容器中运行NodeServer
核心概念
- Docker 镜像(Image)就是一个只读的模板。
- 仓库(Repository)是集中存放镜像文件的场所,
- 容器(Container)是从镜像创建的运行实例。它可以被启动、开始、停止、删除
tips: Docker 和传统虚拟化方式的不同之处, Docker 的基础是 Linux 容器(LXC),容器是在操作系统层面上实现虚拟化,直接复用本地主机的操作系统,而传统方式则是在硬件层面实现。
镜像 ufs 容器
Dockerfile是由一系列命令和参数构成的脚本,这些命令应用于基础镜像并最终创建一个新的镜像。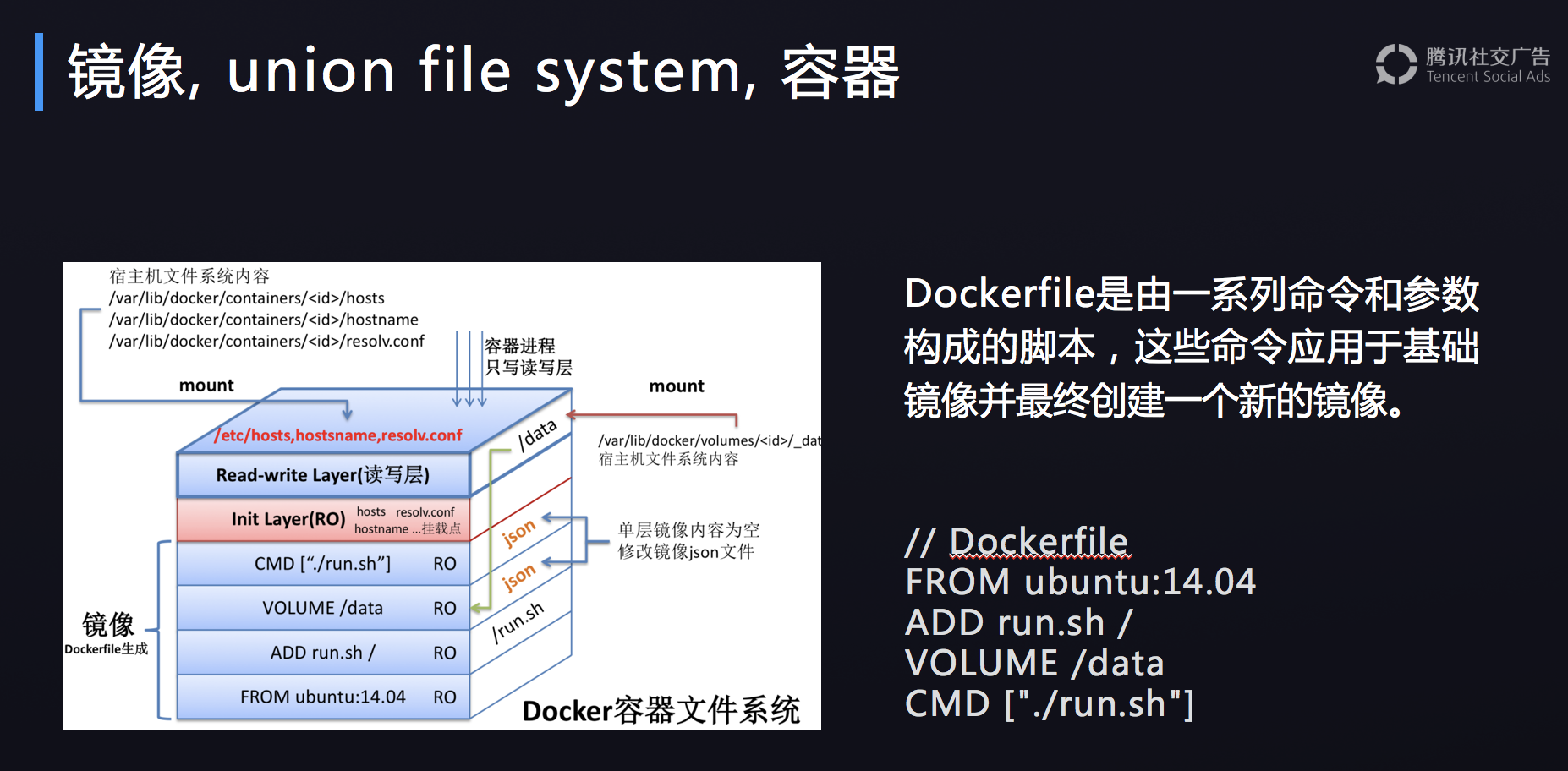
1 | // Dockerfile |
FROM ubuntu:14.04 :设置基础镜像,此时会使用基础镜像 ubuntu:14.04的所有镜像层,为简单起见,图中将其作为一个整体展示。
ADD run.sh /:将Dockerfile所在目录的文件run.sh加至镜像的根目录,此时新一层的镜像只有一项内容,即根目录下的run.sh.
VOLUME /data:设定镜像的VOLUME,此VOLUME在容器内部的路径为/data。需要注意的是,此时并未在新一层的镜像中添加任何文件,但更新了镜像的json文件,以便通过此镜像启动容器时获取这方面的信息。
CMD [“./run.sh”]:设置镜像的默认执行入口,此命令同样不会在新建镜像中添加任何文件,仅仅在上一层镜像json文件的基础上更新新建镜像的json文件。
初始层(Init Layer)与可读写层(Read-Write Layer),初始层中大多是初始化容器环境时,与容器相关的环境信息,如容器主机名,主机host信息以及域名服务文件等。
构建基础镜像与开发部署流程
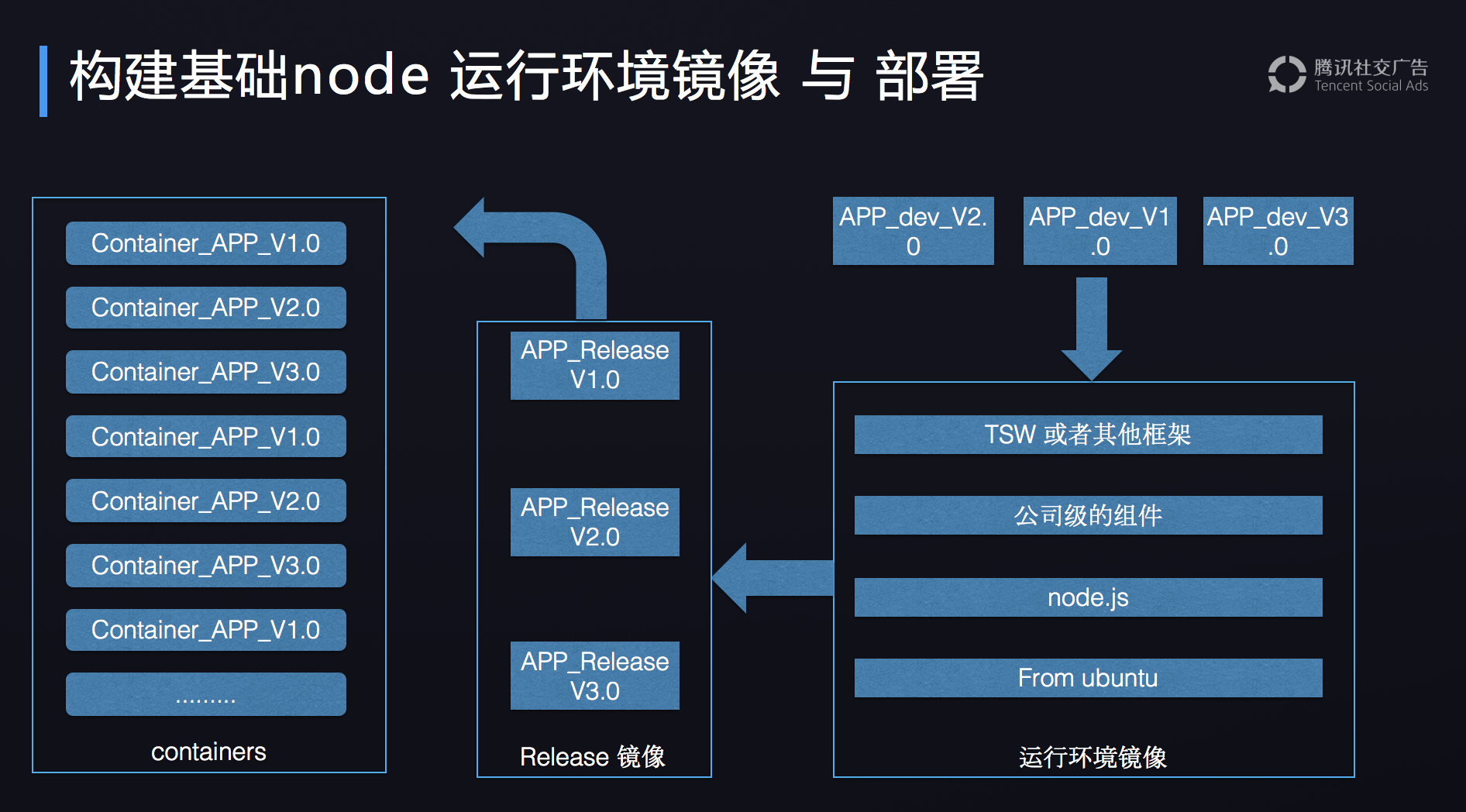
- 开发代码
- 将代码打入现有的基础镜像
- build 出来 release 镜像
- 创建容器运行服务
容器管理与运维
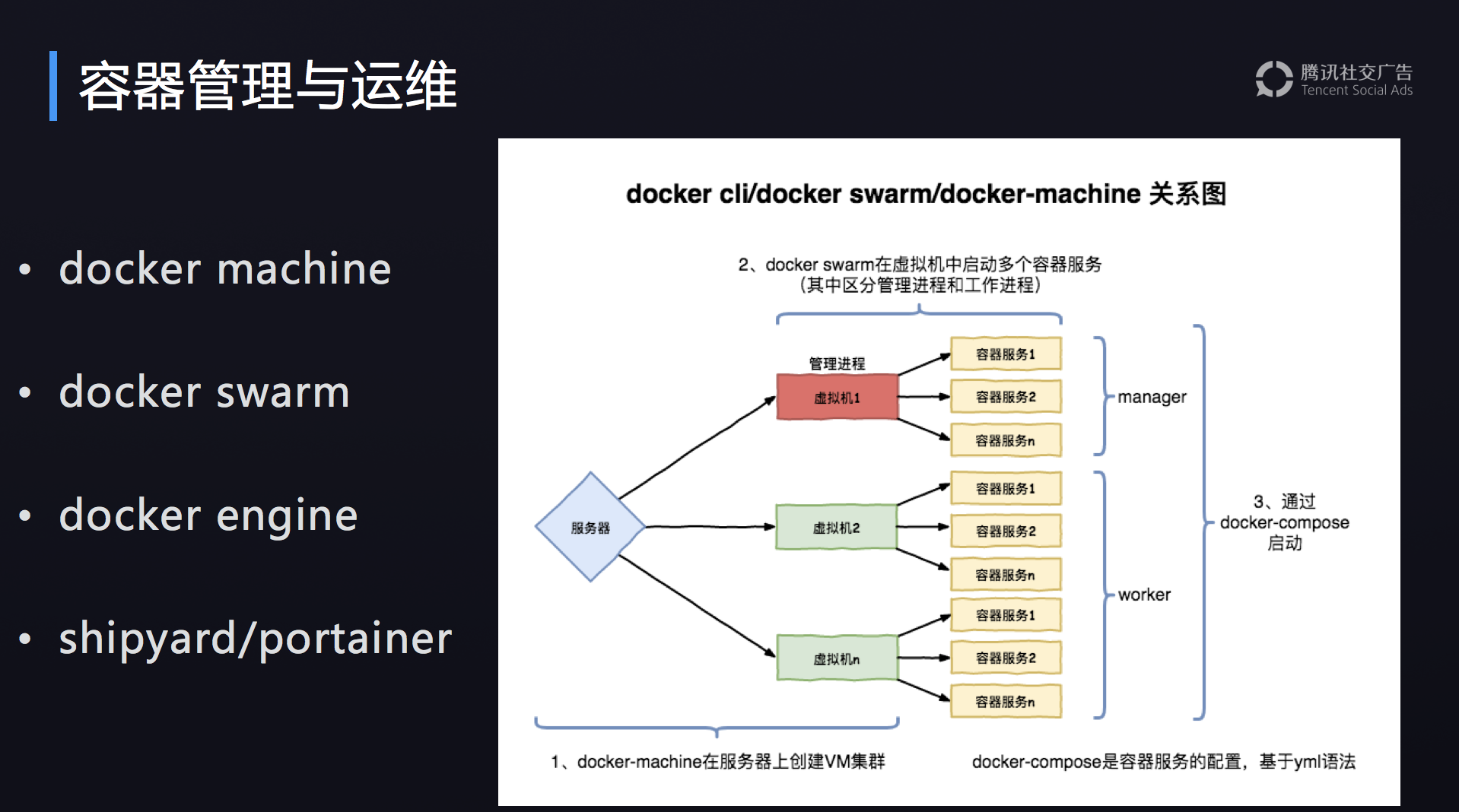
- docker-machine相当于创建了几台可以运行docker的容器
- docker swarm将多个容器做replication
docker engine就是单独的容器执行命令
tips:开源可视化 swarm 容器管理界面
https://github.com/portainer/portainer
https://github.com/shipyard/shipyard
优势
- 告别紊乱的开发环境
- 开发-生产环境,为应用提供了一致的环境
- 应用程序运行环境隔离
- 自带版本控制功能
- 提升研发交付和运维上线效率
- 快速部署
回顾
从部署一个app.js开始, 多维对比 tsw 和tars, 设想Node服务与容器结合, 其实太多的技术细节我们都不了解了, 还是要一步一步慢慢来, 先做好基础技术储备, 一步一个脚印, 从现在的1.0 技术储备时代转向 2.0小规模业务使用的探索时代