背景
在SPAUI提供的众多组件中, Tree树状选择器组件是比较复杂的UI组件之一, 由于前端架构的演进, 老的Tree组件在功能拓展性和兼容性越来越显得吃力. 重构Tree组件似乎越来越有必要了.
在重构Tree组件的过程中, 缩小50%+代码量和提升40%性能的背后是对组件完全重新设计, 包括数据传入处理, 渲染, 事件处理等
写这篇文章的初衷也是为了记录自己在重构Tree组件中的一些思考, 方便后续维护的同学理解它, 同时也希望里面提到的组件设计思想可以被认可并推广
组件的设计理念
1. 组件的能力拓展
随着前端架构的不断演进, 底层的UI组件在项目中的角色也慢慢的发生了改变, 从当初大包大揽的提供尽可能多的功能慢慢转换为提供更好的功能组合能力, 在设计组件的时候, 也要节制, 并非功能越多越好. 太多的组件属性一方面会导致组件自身特殊逻辑很复杂, 不方便拓展; 另外一方面开发者要面对N多自己不关心的属性, 在使用的过程中也容易出现理解偏差;
开发组件就好比建房子, 作为底层的基础组件, 先把房屋的框架搭建好, 至于墙用什么材质, 地板用啥瓷砖, 屋顶盖啥颜色的瓦, 使用者通过子组件的形式传入组合即可, 当然组件本身也要提供默认的子组件组件.
2. 组件的数据管理
组件运行的环境也会影响组件最初的设计, 之前的架构中没有把所有的数据完全用redux管理起来, 组件会把数据在state里面存一份, 然后通过 componentWillReceiveProps 等方法获取数据书更新. 可能一个底层小组件的数据要在父节点里冗余好几份. 更新数据的过程除了性能损耗, 还容易出bug. 由于组件渲染之前会对props做浅对比, 为了防止经常出现数据改变但视图不变的情况, 我们不得不写很多的cloneDeep的逻辑, 深复制是非常耗费性能的. 同时也非常容易出现问题
为了解决系统中的数据管理, 我们做了点小改变
从充血(Smart)组件到贫血(Dumb)组件的转变, 具体的差别是:Smart组件偏向于纯展示,减少组件内置的逻辑, 把更多的逻辑集中到 容器组件(smart组件)或者action和reducer里面
在前端的架构中, 把数据放到全局Store,并且做到数据的immutable, 带来的好处是在架构上更加清晰, 更好的数据流管理, 也减少了很多不必要的渲染, 进而带来了性能上的提升.
3. 往函数式靠拢一点点
1. 使用stateless component
react本身就是函数式编程的一个实践, render方法就是一个 pure function, 满足
view = render(data) 这个公式, 这里要引入stateless component这个概念, 对于很多小的组件我们不需要写成 XXXComponent extends PureComponent 这种形式, 我们只需要定义一个类似下面的方法
1 | const XXXComponent = (props) => return (<div>{props.data}</div>) |
使用stateLessComponent的好处是没有那么多普通组件的生命周期, 优化系统的性能
2. 把数据处理的逻辑抽离出来,独立成 pure function的逻辑
组件在渲染之前避免不了会做一些数据处理的逻辑,如果我们使用函数式的编程思维来看待组件的渲染,一个渲染的逻辑可以用下面这样的一个表达式表示
1 | render(handleData(getData(param))) |
可以看到在整个过程中并没有去设置变量, 每个函数的参数是另外一个函数的返回,整个过程中不会设置变量来暂存上一步的执行结果, 这就是面向过程抽象. 每一个函数都可以被看做独立单元,很有利于进行单元测试(unit testing)和调试(debugging),以及模块化组合.
上面讲了三点的组件设计理念, 在新版的Tree组件中, 我们也在努力的把这些概念落地到实际的组件中
在Tree组件的实践我们的设计理念
tree组件接受的是一个树状的数据, 这里我们把组件分为: 数据处理,组件渲染,事件响应三块
注明:
- 组件内部不保存状态, 所有的数据与状态由父组件通过props传入
- 每次render都会遍历整个树, 时间复杂度为O(n), 因为树的结构比较特殊, 如果一个底层叶子节点选中, 可能会导致整条树枝的元素都是半选的状态
数据处理
直接拿到父组件传入的树状数据直接渲染是不够的, 这里我们扩展一下数据节点的能力, 构建一个属性更多的树.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25/**
* 一个树的节点数据结构
*/
export const treeNodeStruct = {
// 作为数据节点的唯一标识, 如果原始数据有value, 则设为value的值
key: null,
// 节点的的value
value: null,
// 节点的展示文案
desc: null,
// 指向原始数据节点的指针
sourceData: null,
// 指向父节点的指针
parentNode: null,
// 孩子节点数组,里面是一个个treeNodeStruct的指针
childrenNodes: null,
// 节点的 check 状态: checked/unchecked/indeterminate
status: null,
// 节点是否展开子节点
isExpand: null,
// 节点在处在第几个branch, 最左branch为1, 往右递增
deepLevel: null,
// 是否展示loading状态
isLoading: null
}
拿到父组件传入的树状数据之后, 以 treeNodeStruct为节点数据结构的模板,通过 genNodeTree方法, 构建出一个NodeTree的结构.
genNodeTree是一个递归遍历树的方法, 返回一个NodeTree的数据结构, 还有一些树的熟悉比如深度, valueTreeNodeMap等熟悉
这是一个包含更多信息,可用于简化渲染流程的树状数据, 可以快速获取节点的父亲,兄弟节点, 节点选中状态等. 相当于我们把渲染之前数据处理逻辑全部收敛到 genNodeTree这个函数里面.
组件渲染
拿到genNodeTree生成的 NodeTree之后, 就可以开始执行渲染的步骤了, 具体渲染的逻辑可以参考下面函数式的伪代码
1 | let renderOneBranch = compose(map, renderOneNode(TreeNodeComponent)) |
简述一下组件数据处理和渲染流程:
- 遍历由父组件传入的整个的树状数据
- 生成NodeTree, NodeTree的节点以 treeNodeStruct 为结构模板
- 深度遍历仅需要展示的那条路径的节点
事件响应
tree组件在设计的时候开放了两个事件回调接口, onChange 和 onClick
onChange事件:
- 以勾选的节点TreeNode开始, 向上更新父节点链
- 以勾选的节点TreeNode开始, 向下递归更新子节点
- 生成新的 checkedIds, 通过传递到到父组件
- 由父组件传入value重新render
onClick事件:
- 获取点击的节点的所在树的层级
- 生成新的 expandNodeIds, 通过onClick传递到到父组件
- 由父组件传入expandNodeIds重新render
性能
升级完成之后, 可能最大的担心是: 每次全部递归遍历整个树会不会导致性能下降?
直接在浏览器里面做比较吧!
测试中树节点数量为: 3480
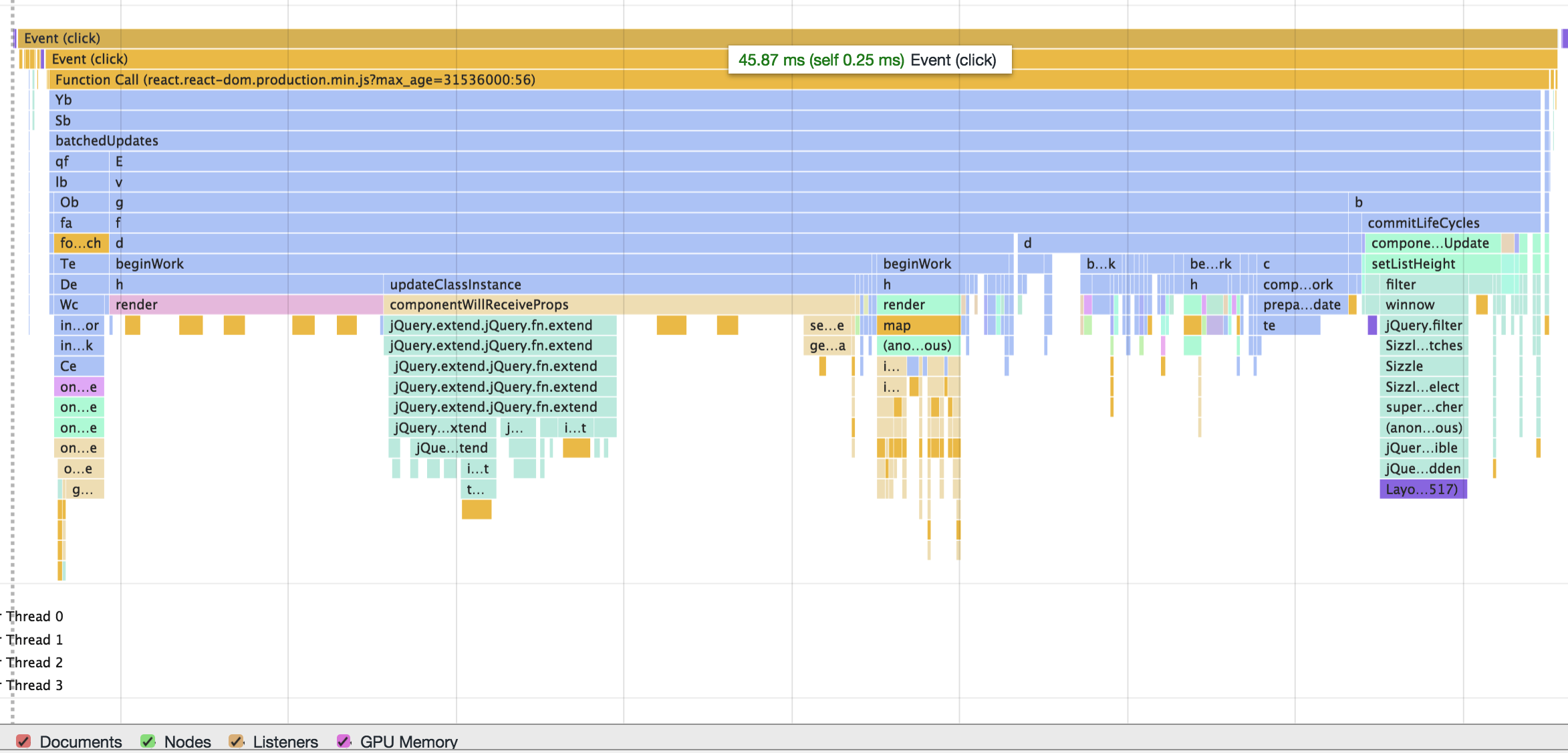
重构之前一次点击节点操作到视图更新, 大约需要45ms的时间
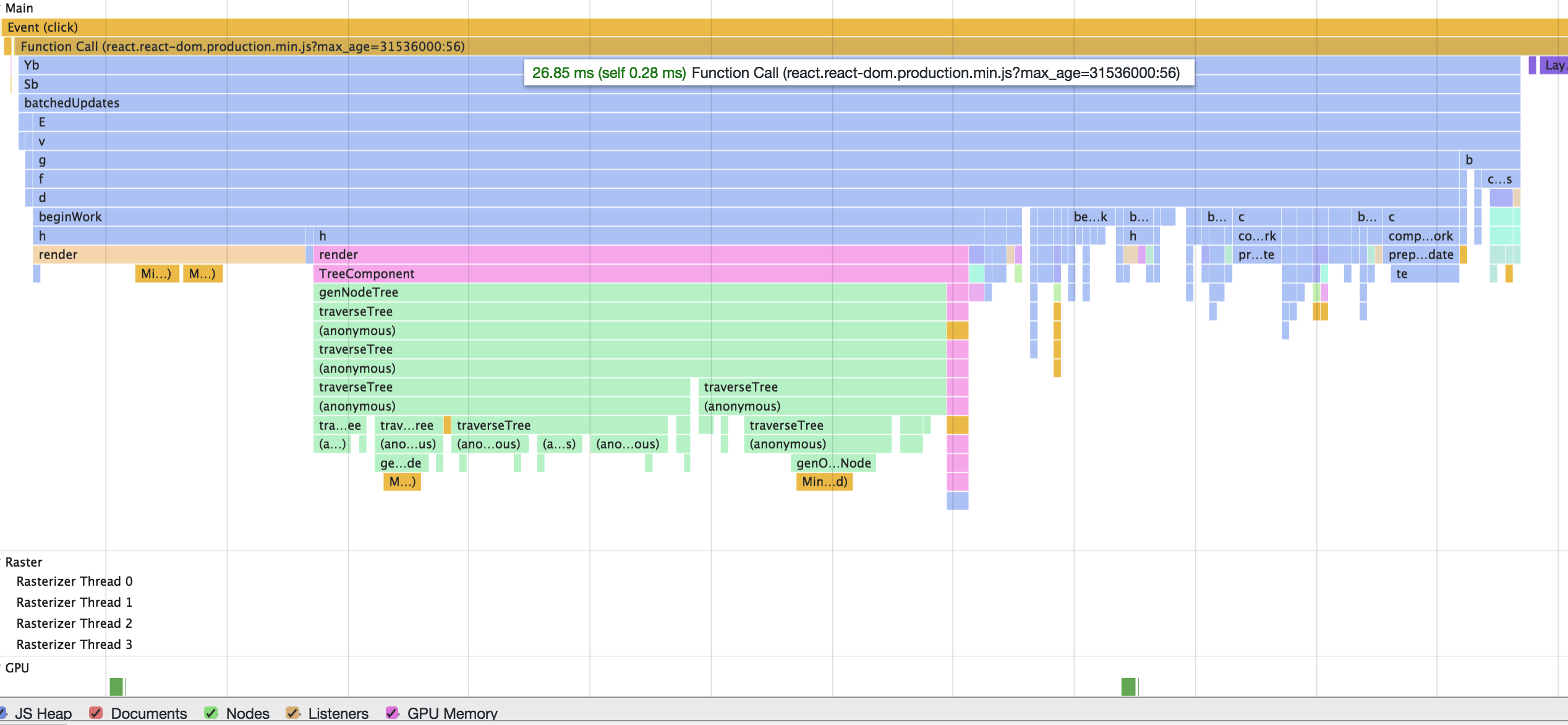
重构之后一次点击到视图更新的操作时间25ms左右, 我们可以看到主要耗时是render这个方法, 因为其中包括对树状数据的遍历操作, 3480个节点大约10s, 这个时间复杂度是 O(n), 随着节点数量呈现线性增长的, 假定浏览器的刷新频率是60Hz, 那么一帧的时间是 16.6666666667ms, 那么树状组件节点只要在5000个以内, 都可以在下一帧被渲染到视图上.
总结
在重构树状组件的过程中, 最开始的目标是把代码结构优化一下方便维护和拓展, 后面吸取了同事们的建议采用新的思路摒弃了老的组件的很多字段, 采用新的设计思想, 特别是在代码层面引入新的函数式思维(最后代码看起来其实也不怎么函数式….), 在完成开发之后做了一下性能测试, 代码减少了50%, 性能提升了45%. 简化代码提升性能, 基本完成了重构Tree组件的初衷. 同时也实践了上述的组件设计思想和函数式的应用.
更多组件相关信息可以参考